GEditBench v2
comprising 22 predefined tasks with an open-set category to evaluate editing models in real-world scenarios.
1Nanyang Technological University2StepFun3Southeast University
Recent advances in image editing have enabled models to handle complex instructions with impressive realism. However, existing evaluation frameworks lag behind: current benchmarks suffer from narrow task coverage, while standard metrics fail to adequately capture visual consistency, i.e., the preservation of identity, structure and semantic coherence between edited and original images. To address these limitations, we introduce GEditBench v2, a comprehensive benchmark with 1,200 real-world user queries spanning 23 tasks, including a dedicated open-set category for unconstrained, out-of-distribution editing instructions beyond predefined tasks. Furthermore, we propose PVC-Judge, an open-source pairwise assessment model for visual consistency, trained via two novel region-decoupled preference data synthesis pipelines. Besides, we construct VCReward-Bench using expert-annotated preference pairs to assess the alignment of PVC-Judge with human judgments on visual consistency evaluation. Experiments show that our PVC-Judge achieves state-of-the-art evaluation performance among open-source models and even surpasses GPT-5.1 on average. Finally, by benchmarking 16 frontier editing models, we show that GEditBench v2 enables more human-aligned evaluation, revealing critical limitations of current models, and providing a reliable foundation for advancing precise image editing.
comprising 22 predefined tasks with an open-set category to evaluate editing models in real-world scenarios.
including 3,506 expert-annotated preference pairs for evaluating assessment models of image editing in visual consistency.
a pairwise assessment model for evaluating editing visual consistency.
two novel region-decoupled preference data synthesis pipelines.
Teaser

Benchmark Samples
Open-Set Instructions

Object Reference

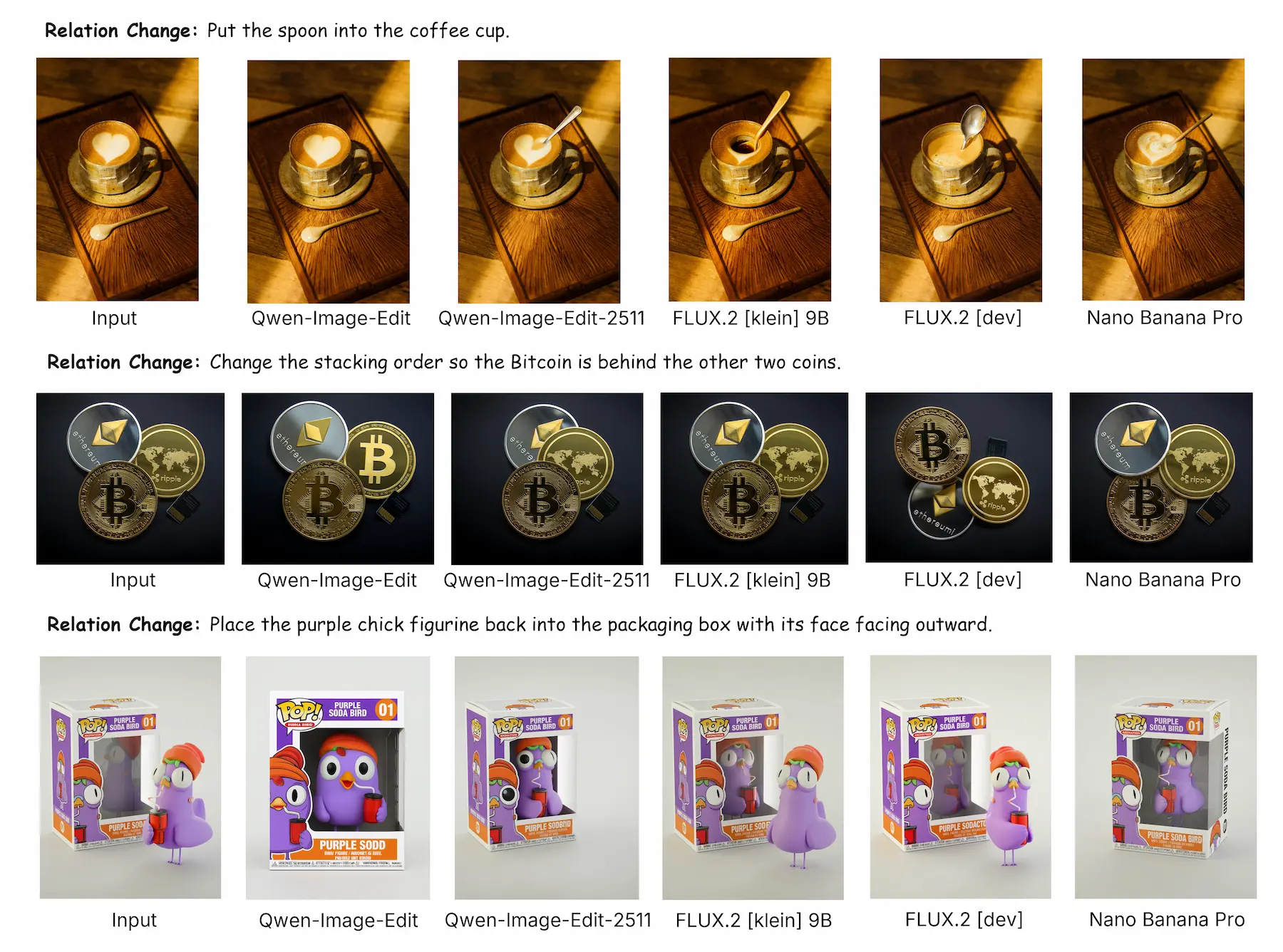
Relation Change

Camera Motion

Text Editing

Chart Editing
Leaderboard
Models are ranked by OVERALL Elo score from pairwise comparisons. Instruction Following and Visual Quality are assessed by GPT-4o, while Visual Consistency is evaluated by PVC-Judge. Confidence Intervals are computed by 1,000 bootstrap iterations. *Arena Elo scores were recorded on March 26, 2026, from Artificial Analysis. Our overall Elo ranking achieves a strong Spearman's rank correlation (ρ = 0.929, p < 2 × 10-7) with the Arena ranking, validating that our automated evaluation ecosystem reliably aligns with human preferences.
| Rank | Model | Source | Samples | InstructionFollowing | VisualQuality | VisualConsistency | Overall | ArenaElo | ArenaRank |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Nano Banana Pro (26-03-04) | Closed | 1,156 | 1,126-13/+15 | 1,066-9/+10 | 1,108-11/+11 | 1,096-6/+6 | 1,251 | #2 |
| 2 | Seedream 4.5 (26-03-11) | Closed | 1,190 | 1,111-12/+12 | 1,142-11/+11 | 1,030-11/+12 | 1,089-7/+7 | 1,196 | #3 |
| 3 | GPT Image 1.5 (26-03-04) | Closed | 1,081 | 1,260-13/+15 | 1,149-12/+12 | 846-13/+13 | 1,071-7/+6 | 1,270 | #1 |
| 4 | FLUX.2 [klein] 9B | Open | 1,200 | 1,083-13/+12 | 1,025-11/+10 | 1,019-10/+9 | 1,039-6/+6 | 1,166 | #4 |
| 5 | Qwen-Image-Edit-2511 | Open | 1,200 | 1,095-10/+10 | 1,060-11/+11 | 972-9/+10 | 1,038-6/+6 | 1,164 | #5 |
| 6 | FLUX.2 [klein] 4B | Open | 1,200 | 1,007-12/+12 | 1,019-10/+10 | 1,070-10/+10 | 1,031-6/+6 | 1,107 | #10 |
| 7 | FLUX.2 [dev] Turbo | Open | 1,200 | 1,068-12/+12 | 936-10/+10 | 1,064-11/+10 | 1,021-6/+6 | 1,153 | #6 |
| 8 | Qwen-Image-Edit-2509 | Open | 1,200 | 1,033-10/+11 | 1,062-10/+12 | 955-9/+9 | 1,014-5/+6 | 1,142 | #7 |
| 9 | Qwen-Image-Edit | Open | 1,200 | 991-10/+10 | 1,073-11/+12 | 971-11/+11 | 1,010-6/+6 | 1,088 | #12 |
| 10 | FLUX.2 [dev] | Open | 1,200 | 1,037-12/+13 | 965-10/+10 | 1,018-11/+11 | 1,006-7/+7 | 1,137 | #8 |
| 11 | LongCat-Image-Edit | Open | 1,200 | 1,018-10/+11 | 968-10/+9 | 1,017-10/+9 | 1,001-6/+5 | 1,111 | #9 |
| 12 | Step1X-Edit-v1p2 | Open | 1,200 | 909-12/+12 | 1,007-12/+11 | 1,067-11/+11 | 996-6/+7 | 1,093 | #11 |
| 13 | GLM-Image | Open | 1,200 | 787-13/+14 | 1,023-11/+11 | 1,109-13/+14 | 979-6/+6 | 930 | #14 |
| 14 | OmniGen V2 | Open | 1,200 | 807-13/+12 | 910-12/+12 | 929-13/+13 | 888-7/+7 | 919 | #15 |
| 15 | FLUX.1 Kontext [dev] | Open | 1,200 | 849-13/+13 | 900-13/+14 | 840-14/+13 | 869-7/+8 | 1,017 | #13 |
| 16 | Bagel | Open | 1,200 | 820-13/+13 | 694-17/+16 | 987-13/+14 | 851-8/+8 | 915 | #16 |
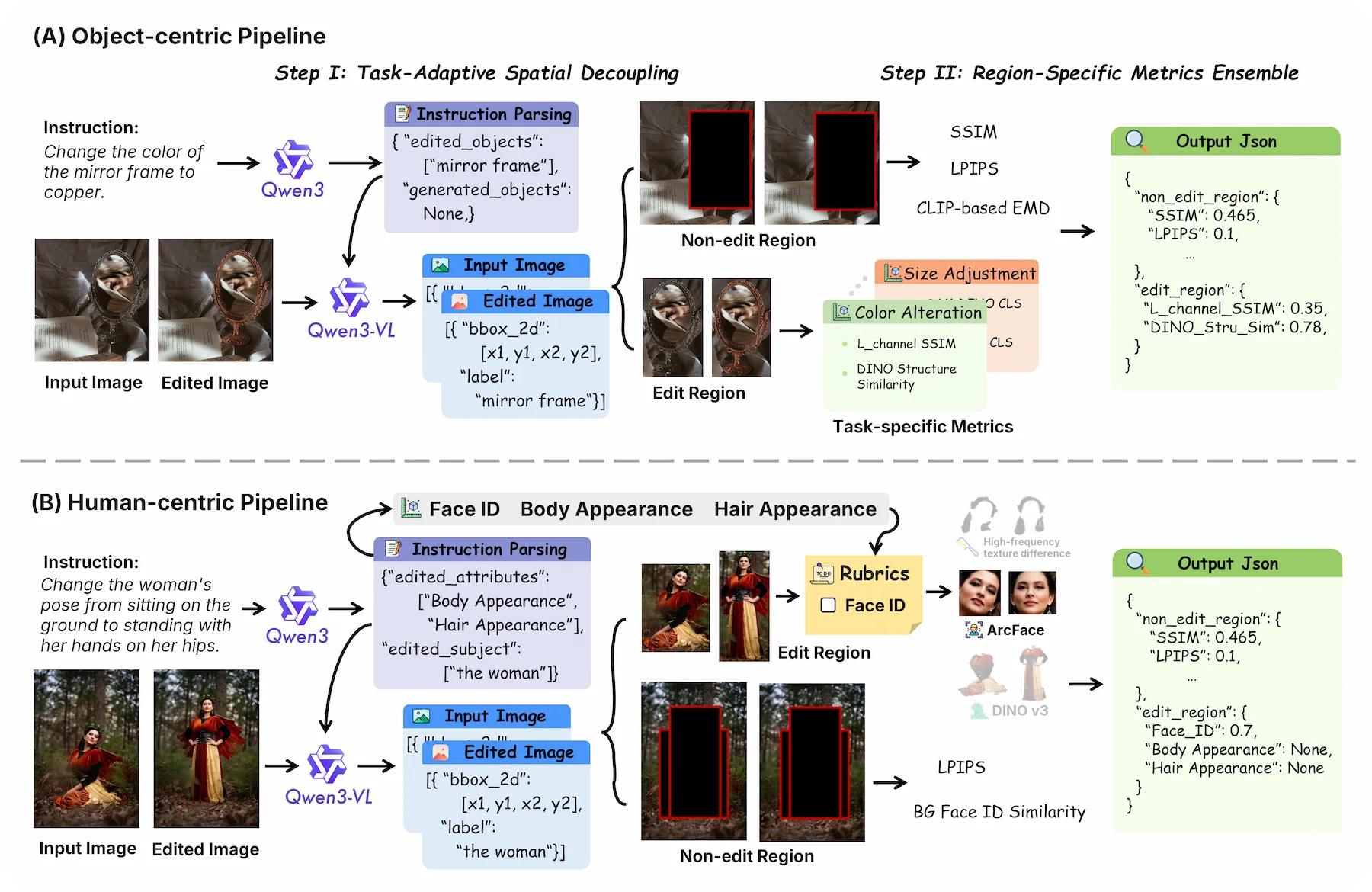
AutoPipeline
AutoPipeline organizes evaluation into task-adaptive pipelines. For object-centric edits, it spatially decouples edited and non-edited regions before applying region-specific metrics; for human-centric edits, it routes face, body, and hair related changes into dedicated evaluation branches and rubric-aware outputs.
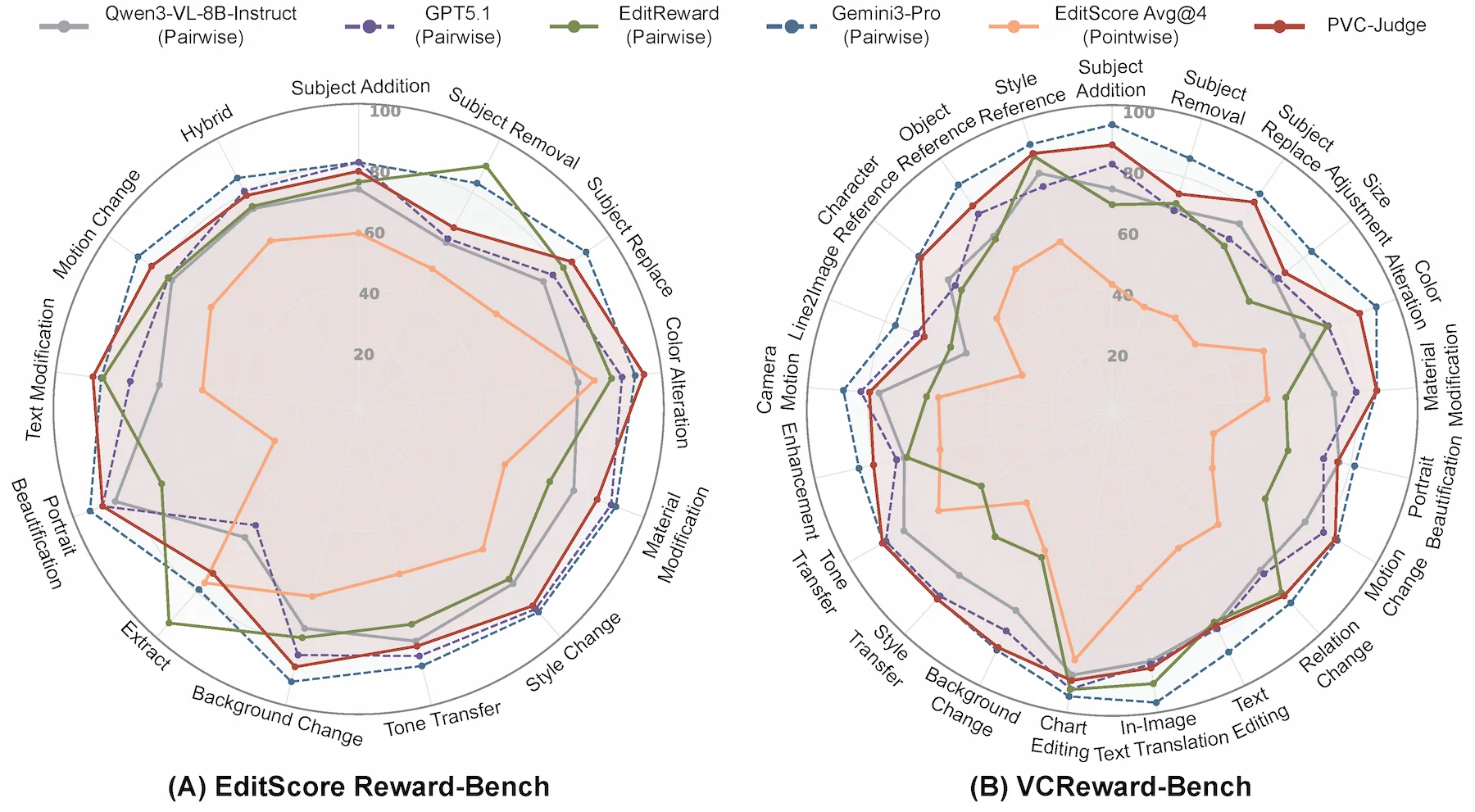
PVC-Judge
We evaluate PVC-Judge on EditScoreReward-Bench and our VCReward-Bench. PVC-Judge achieves strong alignment with human preferences, setting a new state-of-the-art among open-source assessment models and even outperforming GPT-5.1 on average.
Qualitative Analysis
Struggle with Small Faces.
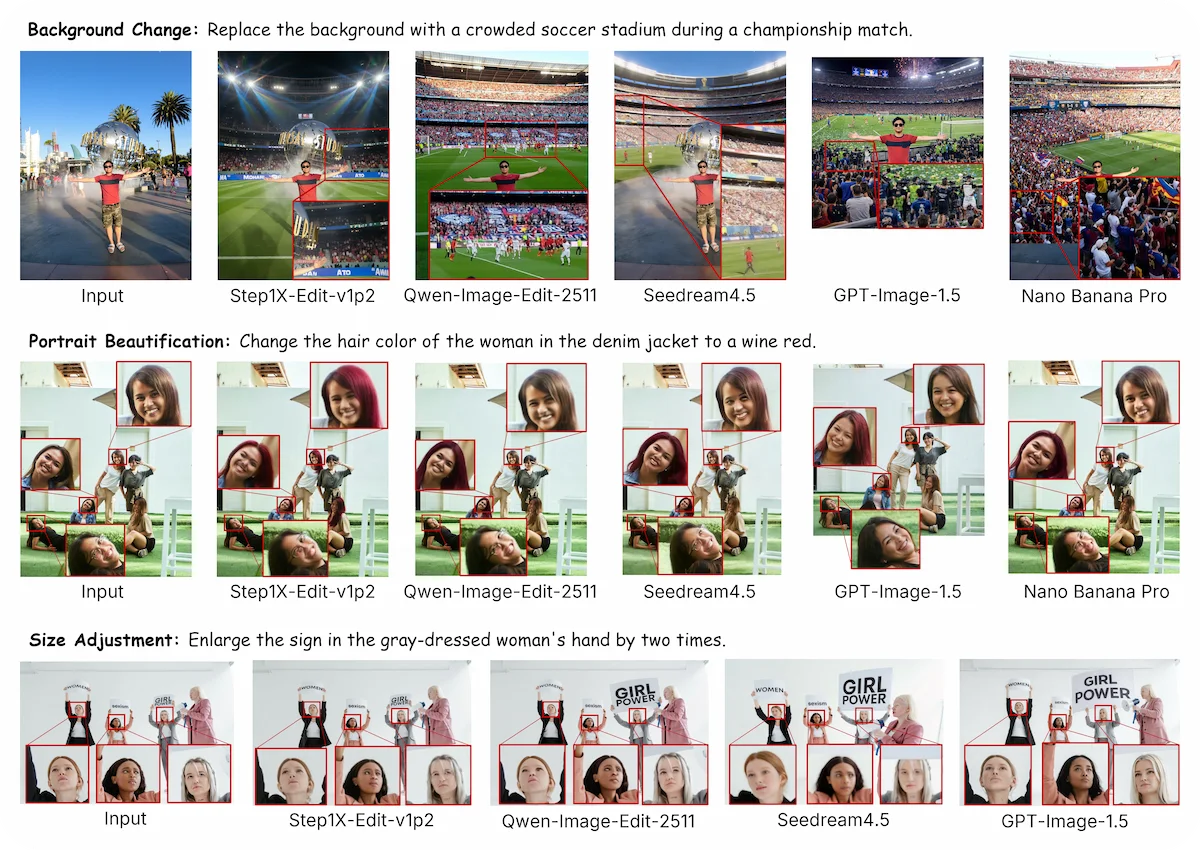
Weak Perception of Inter-Object Relations.
Open-Set Edits
